

开源大语言模型选型指南:一张表看懂主流模型优劣
在实际项目开发中,”选错模型”是导致工程灾难的常见原因之一。通用大模型并非在所有任务上都能发挥最佳表现,每个模型都有其擅长的领域和天然的短板。本文基于一张专为工程师设计的开源大模型选型参考表,对主流开源模型进行全面解析,帮助开发团队做出更合理的选型决策。
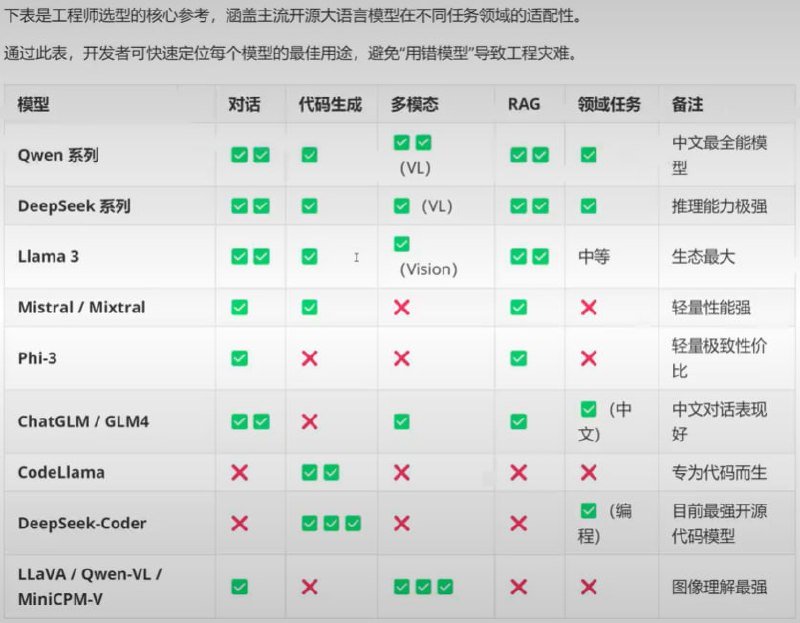
为什么需要模型选型参考?
开源大模型生态近年来发展迅猛,Qwen、DeepSeek、Llama 3、Mistral、GLM4 等模型各具特色,能力覆盖通用对话、代码生成、多模态理解、RAG 检索增强、领域任务等多个维度。
盲目选择模型的代价:
– 用通用对话模型处理代码任务 → 代码补全效果差,调试效率低
– 用非多模态模型处理图像理解 → 完全无法工作
– 用小参数模型做复杂推理 → 幻觉严重,输出不稳定
– 用大参数模型做简单客服 → 成本浪费,响应延迟高
一张清晰的选型对照表,可以帮助团队在项目初期就选对模型,避免后期重构的巨大成本。
评估维度说明
在深入对比之前,先明确这张表格的七个评估维度:
| 维度 | 说明 |
|---|---|
| 对话 | 通用对话、指令遵循能力 |
| 代码生成 | 代码编写、补全、调试能力 |
| 多模态 | 图像理解与视觉信息处理 |
| RAG | 配合外部知识库的检索增强表现 |
| 领域任务 | 特定垂直领域的专业化表现 |
| 备注 | 模型核心优势总结 |
主流开源模型横评对比
1. Qwen(通义千问)— 中文最全能模型
综合评分:✅✅ 对话 | ✅ 代码 | ✅✅ 多模态(VL) | ✅✅ RAG | ✅ 领域任务
Qwen 系列是当前中文开源模型中综合能力最强的选手。对话流畅、中文理解深入、支持视觉语言版本(VL),在 RAG 场景中表现稳定。无论是构建智能客服、还是开发多模态应用,Qwen 都是值得优先测试的选择。
适用场景: 需要兼顾多种能力的综合型项目、中文互联网产品、私有化部署。
2. DeepSeek 系列 — 推理能力极强
综合评分:✅✅ 对话 | ✅ 代码 | ✅ 多模态(VL) | ✅✅ RAG | ✅ 领域任务
DeepSeek 以其强大的推理能力著称,在复杂逻辑推理、数学问题、多步骤任务上表现突出。同时 DeepSeek 系列也具备不错的代码能力和 RAG 适配性,是国产模型中技术深度较高的代表。
适用场景: 需要强推理能力的复杂任务、科学计算、教育类 AI 产品。
3. Llama 3 — 生态最大的国际选手
综合评分:✅✅ 对话 | ✅ 代码 | ✅ 多模态(Vision) | ✅✅ RAG | 中等 领域任务
Llama 3 是 Meta 出品的开源模型,虽然在绝对性能上不一定最强,但其最大的优势在于生态完整性。全球开发者社区围绕 Llama 3 构建了大量的工具链、微调版本、部署方案,从 Ollama 本地运行到云端部署,都有成熟的支持。
适用场景: 需要快速启动、生态工具链支持、国际化产品原型验证。
4. Mistral / Mixtral — 轻量性能强
综合评分:✅ 对话 | ✅ 代码 | ❌ 多模态 | ✅ RAG | ❌ 领域任务
Mistral 系列以其高效率著称,相同参数规模下性能领先。Mixtral 采用稀疏混合专家(MoE)架构,在保持强性能的同时大幅降低了推理成本。缺点是没有多模态能力,不适合视觉相关任务。
适用场景: 对延迟敏感的场景、边缘设备部署、追求性价比的推理服务。
5. Phi-3 — 轻量极致性价比
综合评分:✅ 对话 | ❌ 代码 | ❌ 多模态 | ✅ RAG | ❌ 领域任务
Phi-3 是微软出品的小型化模型,主打极致性价比。虽然在对话和简单 RAG 任务上表现尚可,但完全没有代码和多模态能力,更适合资源受限或简单场景下的轻量级应用。
适用场景: 端侧部署、移动端嵌入、简单问答机器人。
6. ChatGLM / GLM4 — 中文对话专家
综合评分:✅✅ 对话 | ❌ 代码 | ✅ 多模态 | ✅ RAG | ✅ 中文 领域任务
GLM4 在中文对话任务上表现优异,对中国市场的本土化场景理解深入,中文语义理解准确。是智谱 AI 的拳头产品,在国内企业应用中有大量落地案例。
适用场景: 国内企业级对话系统、中文垂直领域应用、政务/教育类AI产品。
7. CodeLlama — 专为代码而生
综合评分:❌ 对话 | ✅✅ 代码 | ❌ 多模态 | ❌ RAG | ❌ 领域任务
CodeLlama 是 Llama 2 的代码专化版本,在代码补全、代码生成、代码审查任务上表现出色。但作为代价,它的通用对话能力几乎为零,也不支持多模态和 RAG——这是典型的”专才”模型。
适用场景: IDE 代码补全插件、代码审查工具、自动化测试生成。
8. DeepSeek-Coder — 目前最强开源代码模型
综合评分:❌ 对话 | ✅✅✅ 代码 | ❌ 多模态 | ❌ RAG | ✅ 编程 领域任务
DeepSeek-Coder 是目前开源代码模型的性能天花板,获得了最高的三绿钩评价。它不仅在通用代码任务上领先,还特别针对编程领域任务进行了强化训练。如果你需要纯代码能力的模型,这是目前最好的开源选择。
适用场景: 专业代码生成服务、编程学习辅助、自动化代码修复。
9. LLaVA / Qwen-VL / MiniCPM-V — 图像理解最强
综合评分:✅ 对话 | ❌ 代码 | ✅✅✅ 多模态 | ❌ RAG | ❌ 领域任务
这是一类专注于多模态视觉理解的模型家族,在图像问答、视觉推理、文档扫描等任务上达到开源界的顶尖水平。但作为专才模型,它们在其他维度上几乎全面落后。
适用场景: 视觉问答系统、文档 OCR 处理、图像内容分析、工业视觉检测。
选型决策树
根据这张图,我们可以总结出一个快速的选型决策逻辑:
项目需要什么能力?
├── 通用对话 + 中文支持
│ ├── 追求全能 → Qwen
│ ├── 追求推理 → DeepSeek
│ └── 中文垂直 → GLM4
├── 纯代码能力
│ ├── 顶级代码 → DeepSeek-Coder
│ └── 辅助代码 → CodeLlama
├── 多模态/视觉
│ ├── 图像理解 → LLaVA / Qwen-VL / MiniCPM-V
│ └── 通用 + 视觉 → Qwen (VL版本)
├── RAG 检索增强
│ └── Qwen / DeepSeek / Llama 3
├── 轻量/边缘部署
│ └── Mistral / Phi-3
└── 追求生态丰富
└── Llama 3
总结
开源大模型没有绝对的”最强”,只有最适合特定场景的选择。作为工程师,我们应该:
- 先明确任务需求 — 是对话、代码、视觉还是RAG?
- 测试优先 — 在正式项目前,用真实数据测试几个候选模型
- 考虑工程约束 — 延迟、显存、部署成本、团队技术栈
- 保持灵活性 — 模型迭代快,不要过度绑定某个模型
选对模型,是AI应用成功的一半。

