

大模型任务空间全景:为什么AI正在走向专业化分工?
本文根据一张关于”大模型任务空间全景”的演示幻灯片,深入解析当前大模型生态的分工体系,帮助开发者和企业在实际项目中做出更合理的大模型选型决策。
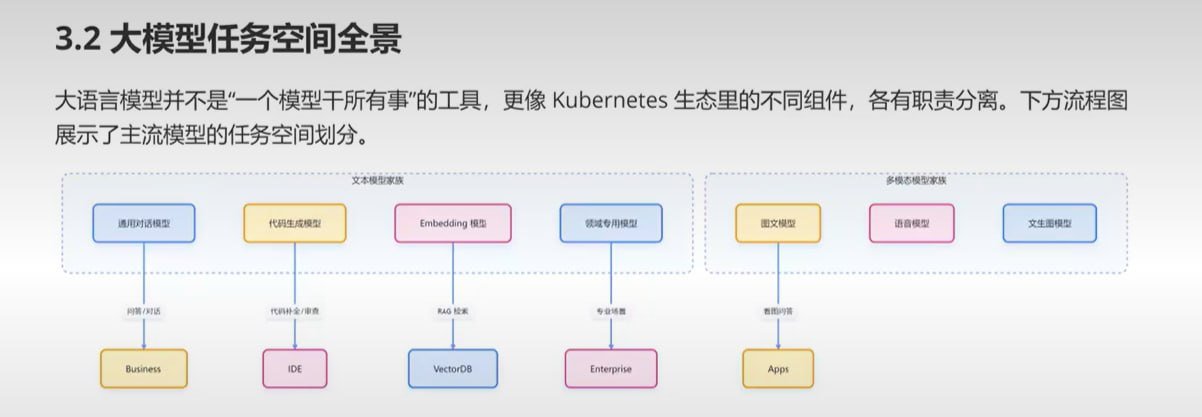
一、核心观点:大模型并非”万能工具”
在过去的几年里,”大模型”几乎成为了AI的代名词。从ChatGPT到GPT-4,从Claude到Gemini,这些通用大语言模型展示了令人惊叹的问答、写作、推理能力。这让许多人产生了一种错觉:大模型可以解决所有问题。
然而,事实并非如此。
大模型生态正在加速演进为一个高度专业化的分工体系,其内部结构与云计算领域的Kubernetes(K8s)生态极为相似——不同组件有明确的职责边界,一个组件无法替代另一个组件完成特定任务。
理解这一点,对于AI项目的成功落地至关重要。
二、大模型任务空间全景图
当前主流大模型可以划分为两大家族:文本模型家族(Text Model Family) 和 多模态模型家族(Multimodal Model Family)。每个家族内部又根据任务类型进一步细分。
2.1 文本模型家族(Text Model Family)
文本模型是目前最为成熟、应用最为广泛的大模型类别。这一家族内部按照任务类型可以细分为以下四个主要子类别:
1. 通用对话模型(General Chat Model)
- 代表模型:GPT-4、Claude、ChatGPT、国产的通义千问、文心一言等
- 核心能力:问答、对话、文本生成、内容创作
- 具体任务:处理开放域问答、写作辅助、翻译、摘要等通用文本任务
- 落地场景:Business(商业应用)—— 客服系统、内容创作平台、办公自动化等
这是大多数人接触最多的模型类型。它们的特点是泛化能力强,能够处理多种类型的文本任务,但在特定垂直领域的专业深度上可能不如专用模型。
2. 代码生成模型(Code Generation Model)
- 代表模型:GitHub Copilot(基于GPT-4)、Claude Code、Cursor、Windsurf、Devin等
- 核心能力:代码补全、代码审查、Bug修复、代码解释
- 具体任务:根据自然语言描述生成代码、代码补全、代码重构
- 落地场景:IDE(集成开发环境)—— 开发者工具、代码编辑器插件
代码生成模型与通用对话模型的核心区别在于:代码模型经过专门的代码数据训练,对代码语法、API调用、代码风格有更深入的理解。它们不仅仅是”写代码”,还能理解代码的执行逻辑和依赖关系。
3. Embedding模型(嵌入模型)
- 代表模型:OpenAI的text-embedding-ada-002、Cohere Embeddings、国产的M3E、BGE等
- 核心能力:将文本转换为高维向量表示,用于语义相似度计算
- 具体任务:RAG(检索增强生成)、文本聚类、相似度搜索、推荐系统
- 落地场景:VectorDB(向量数据库)—— Pinecone、Milvus、Chroma、Qdrant等
这是大模型能力体系中最容易被人忽视,却最为关键的组件之一。Embedding模型负责将文本”数字化”,为RAG系统提供语义理解的基础设施。没有高质量的Embedding,再强大的生成模型也难以实现精准的检索增强。
4. 领域专用模型(Domain-Specific Model)
- 代表模型:医疗领域的Med-PaLM、法律领域的Clausie、金融领域的BloombergGPT等
- 核心能力:特定垂直领域的深度知识、专业术语理解、领域推理
- 具体任务:专业场景问答、领域知识推理、专业文档分析
- 落地场景:Enterprise(企业级应用)—— 医疗辅助诊断、法律文书分析、金融风控等
通用模型在垂直领域的深度和专业性上,往往不如经过领域数据专门训练的专用模型。领域专用模型的核心价值在于对专业知识的深度理解和准确应用。
2.2 多模态模型家族(Multimodal Model Family)
多模态模型是近年来发展最为迅速的大模型方向,其核心特点是能够同时处理多种模态的信息输入,如文本、图像、音频、视频等。
1. 图文模型(Vision-Language Model)
- 代表模型:GPT-4V、Claude 3 Vision、Gemini Pro Vision、国产的通义千问VL等
- 核心能力:理解图像内容、看图问答、图表分析、文档扫描
- 具体任务:基于图像的问答、图像描述生成、视觉推理、OCR增强
- 落地场景:Apps(各类移动或网页应用)—— 智能相册、AI相机、内容审核等
图文模型打破了纯文本模型的局限,使AI能够”看懂”世界。这一能力在很多场景下具有不可替代的价值,例如处理截图、扫描文档、分析图表等。
2. 语音模型(Speech Model)
- 代表模型:Whisper(语音识别)、Azure TTS、Coqui TTS(语音合成)、GPT-4o(语音交互)等
- 核心能力:语音识别(ASR)、语音合成(TTS)、语音对话
- 落地场景:语音助手、播报系统、语音客服等
语音模型的核心价值在于实现人类与AI的自然语音交互,目前已在智能助手、语音客服、有声内容生成等场景广泛落地。
3. 文生图模型(Text-to-Image Model)
- 代表模型:Midjourney、DALL-E 3、Stable Diffusion、Adobe Firefly、国产的即梦、可图等
- 核心能力:根据文本描述生成高质量图像
- 落地场景:创意设计、广告营销、游戏美术、内容创作等
文生图模型是AIGC(AI生成内容)的重要组成部分,其核心价值在于大幅降低高质量视觉内容的创作门槛。
三、为什么大模型走向专业化分工?
3.1 能力边界的客观约束
当前的大模型技术,即使是参数规模最大的GPT-4、Claude 3,在面对所有类型的任务时,并非都能做到最优。专业化分工是对能力边界的理性适配。
- Embedding模型无法直接生成文本,但能为RAG系统提供精准的语义检索能力
- 代码生成模型在通用对话上可能不如ChatGPT,但在代码补全、代码审查上远超通用模型
- 领域专用模型在专业任务上远超通用模型,因为它们消耗了大量领域数据进行了专门训练
3.2 工程落地的现实需求
在实际项目中,成本、延迟、精度是三个核心约束:
| 需求 | 最优选择 |
|---|---|
| 通用问答 | 通用对话模型 |
| 代码补全 | 代码生成模型 |
| 私域知识问答(RAG) | Embedding模型 + 通用对话模型 |
| 专业领域咨询 | 领域专用模型 |
| 看图理解 | 图文模型 |
| 语音播报 | 语音模型 |
| 生成配图 | 文生图模型 |
使用单一通用模型解决所有问题,往往意味着在每个任务上的性价比都不是最优的。
3.3 生态系统成熟的必然结果
就像云计算领域从”大一统”走向”微服务+K8s”的分工体系一样,大模型生态也在经历相似的演进。专业化分工是技术成熟的标志,也是生态繁荣的基础。
四、大模型选型的实用建议
基于以上分析,以下是一些实用的选型建议:
4.1 通用对话场景
选择通用对话模型(GPT-4、Claude、通义千问等),优先考虑上下文长度、推理能力和成本。
4.2 代码相关场景
选择专门的代码生成模型(GitHub Copilot、Cursor等),IDE集成能力强,实际开发效率远高于通用模型。
4.3 RAG系统场景
这是最容易被低估的场景。Embedding模型的选择直接影响RAG系统的检索质量。建议在Chroma、Milvus等向量数据库中测试不同Embedding模型的效果,选择最适合自己数据特点的模型。
4.4 专业领域场景
优先考虑领域专用模型,或使用通用模型+高质量领域知识库的方式。如果领域数据足够丰富,可以考虑微调(Fine-tuning)通用模型。
4.5 多模态场景
根据具体模态选择对应模型。需要强调的是,多模态能力目前仍处于快速发展阶段,建议持续关注最新模型的性能提升。
五、总结
大模型并非”万能工具”,而是正在形成一个高度专业化、分工明确的生态体系。理解这一体系,是做出正确AI选型决策的前提。
未来的AI应用,将不是”选择一个最强的大模型”,而是构建一个由多个专业化模型组件组成的系统,每个组件各司其职、协同工作。就像今天的软件系统不会用一台服务器跑所有服务一样,AI系统也需要专业化的架构设计。
核心 takeaways:
- 通用模型不是万能的—— 每个模型都有其能力边界
- 专业化分工是必然趋势—— K8s生态就是前车之鉴
- RAG系统中Embedding被严重低估—— 检索质量决定生成质量
- 代码任务用专用代码模型—— 开发效率远超通用模型
- 多模态是重要方向—— 图文、语音、文生图各有专注场景
希望这篇文章能帮助你在实际项目中做出更好的大模型选型决策。

