

Neo X Go-Ethereum 项目架构概览
基于 Go Ethereum 的 Neo X 节点架构详解,包含核心目录结构、关键组件、以太坊服务、区块链核心、共识引擎等模块的交互关系。
Neo X Go-Ethereum 项目架构概览 Read More »
基于 Go Ethereum 的 Neo X 节点架构详解,包含核心目录结构、关键组件、以太坊服务、区块链核心、共识引擎等模块的交互关系。
Neo X Go-Ethereum 项目架构概览 Read More »

go-ethereum 是以太坊网络的官方全节点客户端,本文深入分析其整体架构、核心模块、关键机制及常用命令。
go-ethereum 项目分析:以太坊官方 Go 实现深度解读 Read More »
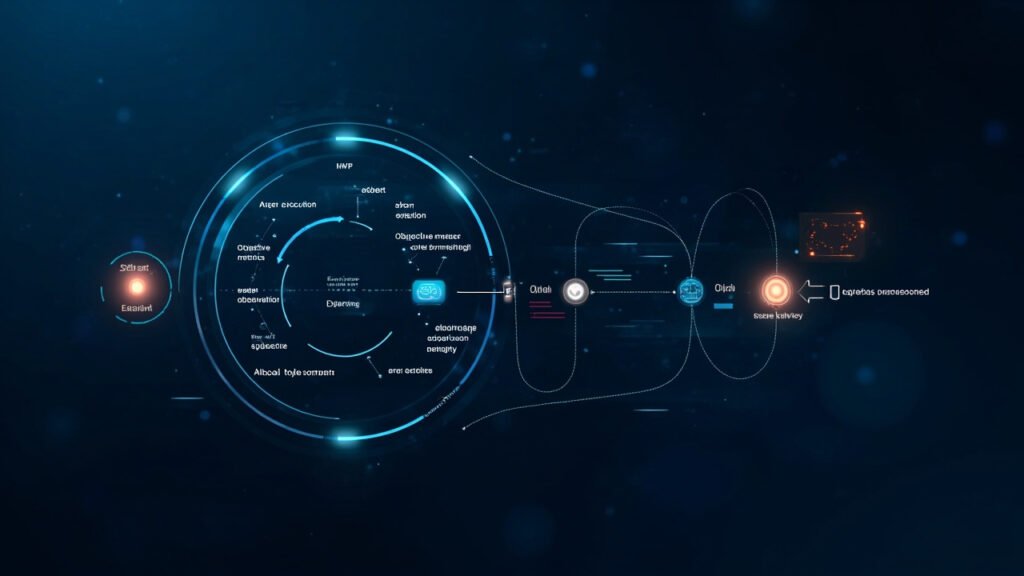
AI Agent 的开发有一个根本性问题:开发者往往难以判断 Agent 在真实任务中的实际表现——它到底做对了什么?做错了什么?下一次迭代该改进哪里?传统的方法是靠人工抽查和主观感受,但当 Agent 的能力边界逐步扩展时,这种”盲测”越来越不可靠。 ▲ 评测驱动开发(EDD)闭环:运行→提炼指标→多维度评测→反馈改进 EDD 核心:反馈闭环 EDD 的本质是一个持续迭代的优化闭环:MVP 启动 → 真实运行 → 观察错误与提炼指标 → 多维度评测 → 结果汇总 → 反馈改进。虚线箭头代表的就是这个反馈循环——它不是一次性流程,而是永续进行的迭代。 指标分为两类:客观指标(可运行性、格式合规、字数长度)直接自动检测;主观指标(准确性、数学逻辑、风格倾向)通过 LLM 评测和人工评测交叉验证。 为什么要区分主客观指标? EDD 的高明之处在于:用 LLM 做裁判来评测主观指标。GPT-4 或同类大模型可以扮演”评审官”角色,对内容的准确性、逻辑性、风格一致性给出评分。重要场景下依然保留人工评测通道,确保高风险错误不被漏过。 AgentScope 评测框架实践 AgentScope 给出生产级参考实现:输入课程基准 → 生成 Agent(产出章节草稿:标题、教学目标、代码示例、测验)→ 评审 Agent(独立审核)→ 五维度量化评分结果。生成与评审分离、主客观结合,让优化有的放矢。 EDD 的工程价值 从主观直觉到数据驱动:每一次迭代都有了客观的量化基准。 从全局盲测到定向改进:评测报告清晰指出 Agent 在哪些指标上表现不佳。 从单次交付到持续进化:Agent 可以在实际使用中不断积累评测数据,越用越精准。 结语 EDD 解决的不是”Agent 能力强不强”的问题,而是”团队能否看清
评测驱动开发:如何用数据闭环让AI Agent越用越强? Read More »
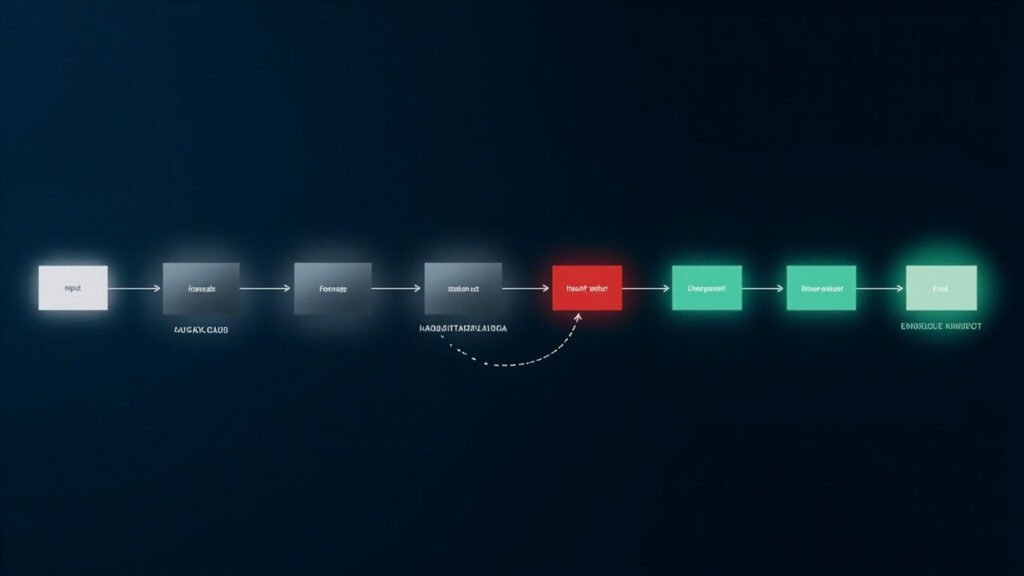
当AI系统在真实场景中落地,最大挑战往往不是模型能力本身,而是不确定性——模型在面对模糊边界、高风险决策或训练数据覆盖不足的场景时,往往以高置信度输出错误结果而不自知。人机协作(Human-in-the-Loop,简称HITL)正是为解决这一问题而生。 ▲ HITL人机协作工作流:AI自动处理与人类专家审核的协同流程 什么是 HITL? HITL的核心思想很直观:在AI自动化流程的关键节点,系统性地引入人类判断。这不是全程让人参与,也不是完全放手让AI自主决策——而是在”AI最需要帮助”的时刻,让人类专家介入纠偏。 HITL 工作流解析 一个典型的HITL流程包含以下节点:初始输入(课程内容)→ AI分析师(给出建议)→ AI改写器(执行修改)→ 人类专家(在”不确定时”介入审核)→ 最终输出。 关键机制是不确定性触发:AI改写器在完成后会自我评估置信度,若结果在可接受范围内则自动流转;若判定为高不确定性,则主动向人类专家发起求助。这种条件触发确保了人类介入的精准性,而非低效地全程跟随。 为什么 HITL 是构建可信AI的关键? HITL通过三个层面化解AI风险:安全护栏(关键节点设置人类审核关卡,确保高风险输出不被直接放行)、价值对齐(人类价值观注入决策过程)、持续进化(每一次纠偏都是高质量强化学习信号)。 HITL 的适用边界 HITL不适合:完全自动化的低风险任务、需要高速响应的实时场景、以及人类自身也无法判断的领域。适合的场景通常具有”容错空间小、边界模糊、后果重大”的特点——如医疗诊断辅助、法律文书审核、金融风控决策等。 结语 HITL代表了一种务实的AI落地哲学:承认AI不是万能的,在它最需要帮助的时刻让人发挥价值。灰(AI)→ 红(人类) → 绿(成果),三种颜色勾勒出可信AI系统的基本色。这不是对AI能力的否定,而是对AI局限的清醒认知与系统性应对。
人机协作新范式:HITL如何让AI系统真正可信? Read More »

通过分析师、审查官、聚合器的三层分工,多智能体系统实现了近似人类专家团队的高质量协作决策。这种范式正在重新定义大模型在复杂任务中的使用方式。
多智能体协作新范式:分析师-审查官-聚合器三层工作流解析 Read More »

本文详细对比了2026年主流六大LLM模型族的核心能力、优势与短板,并给出基于语言、场景、部署方式的选择建议。
2026年主流大模型族优缺点全面对比:如何选择最适合的底座模型 Read More »

为工程师量身打造的开源大语言模型选型参考,涵盖Qwen、DeepSeek、Llama3等9类主流模型的横评对比,帮你快速定位最适合的模型。
开源大语言模型选型指南:一张表看懂主流模型优劣 Read More »

大模型并非万能工具。本文深入解析当前大模型生态的分工体系,涵盖文本模型家族(通用对话/代码生成/Embedding/领域专用)和多模态模型家族(图文/语音/文生图),帮助开发者和企业在实际项目中做出更合理的大模型选型决策。
大模型任务空间全景:为什么AI正在走向专业化分工? Read More »
https://leetcode.cn/problems/generate-parentheses/description 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n = 3 输出:[“((()))”,”(()())”,”(())()”,”()(())”,”()()()”] 示例 2: 输入:n = 1 输出:[“()”] 提示: 思路: 递归, 满足条件有: 左括号和右括号数量之和为2*n; 递归过程中左括号数量小于n则可以加左括号DFS, 若右括号数量小于左括号则可以加右括号DFS C#实现:
https://leetcode.cn/problems/valid-parentheses/description 给定一个只包括 ‘(‘,’)’,'{‘,’}’,'[‘,’]’ 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 示例 1: 输入:s = “()” 输出:true 示例 2: 输入:s = “()[]{}” 输出:true 示例 3: 输入:s = “(]” 输出:false 示例 4: 输入:s = “([])” 输出:true 示例 5: 输入:s = “([)]” 输出:false 提示: 思路:栈 C#实现: